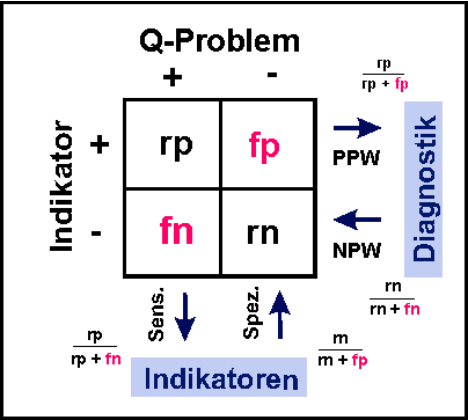
Um Parameter, die als Indikatoren in Frage kommen, weiter zu charakterisieren, stehen Zuverlässigkeit (Reliabilität: wird der
Parameter richtig bestimmt?) und Validität (werden die Qualitätsprobleme identifiziert, die vorliegen, wird also das gemessen,
was gemessen werden soll?) im Vordergrund (s. Abb. 2). Auch in
unserer aktuellen deutschen Diskussion werden Reliabilität und
Validität oft nicht korrekt getrennt. Wenn etwa bemängelt wird,
Indikatoren seien deswegen nicht geeignet (nicht valide, erfüllen
nicht ihre Vorhersagefunktion), weil sie wegen
Dokumentationsmängeln (nicht reliabel) falsche Ergebnisse
erbringen, dann ist hier zunächst eine Aussage zur Reliabilität
und nicht zur Validität gemacht (z.B. Petzold et al. 2013).
Natürlich kann ein nicht reliabler Indikator kaum valide sein;
können jedoch die Probleme in der Reliabilität behoben werden,
dann kann durchaus eine hervorragende Validität vorliegen. Und
natürlich haben unsere Erhebungsmethoden z.B. in der
Qualitätssicherung nach §137 SGB V massive
Reliabilitätsprobleme, basieren sie doch weitgehend auf
freiwilligen Selbstauskünften, die nur schlecht durch unabhängige
und unangemeldete Stichproben “geeicht” sind. Besonders gut ist
der Einfluss der Messmethodik auf das Ergebnis der Erhebungen
bei den unerwünschten Ereignissen auf dem Gebiet der Patientensicherheit dokumentiert. Durch freiwillige Meldung werden
nur 1% der relevanten, mit negativen Konsequenzen für den Patienten verbundenen adverse events entdeckt (Classen et al.
2011).
Bei der Validität (zusammenfassende Darstellung der Anforderungen s. Schrappe
2010) wird der Sensitivität der Vorzug gegenüber der Spezifität gegeben (man will
alle Qualitätsprobleme erkennen und hat nichts dagegen einzuwenden, “umsonst
gerufen worden zu sein”, vgl. Tableau 7 und Abb. 3). Aber auch valide Indikatoren
können im konkreten Messzusammenhang nutzlos sein (Abb. 2), so befinden wir
uns bei §137-Indikatoren schon nahe am Optimum, eine weitere Verbesserung der
Indikatoren (nicht der Versorgung) ist kaum noch möglich (sog. ceiling-Effekt)
(AQUA 2013). Dies kann auch die Konsequenz haben, dass wir einen positiven
Effekt von P4P deswegen nicht erkennen, weil wir auf dem Hintergrund der
intensiven Beschäftigung mit dem Thema gleichzeitig zu einer Verbesserung
unserer Messmethodik (scheinbare Zunahme von Qualitätsdefiziten) kommen und
hiermit den Erfolg (tatsächliche Abnahme von Qualitätsdefiziten) verdecken. Auch
muss, wie von Szescenyi und Mitarbeitern immer wieder hervorgehoben wird, eine
hohe Relevanz und Umsetzbarkeit von Indikatoren gegeben sein (Willms et al.
2013). Es hat wenig Sinn, einen Indikator zu implementieren, der auf
Qualitätsdefizite verweist, die nicht abänderbar sind (z.B. außerhalb des
institutionellen Kompetenzrahmens liegen), sondern es sollten ”Qualitätspotentiale”
existieren.
weiter: 1. Einleitung, 1.5. Konzeption und Gesundheitssystem











Seite
Kapitel


Seite
Kapitel
1. Einleitung
1.4. Zum Begriff des Indikators
Abb. 2: Begriff des Indikators. Neben Reliabilität und
Validität muss das Problem definiert sein, das der
Indikator beobachten soll. Dieses muss veränderbar sein.
© Prof. Dr. med. Matthias Schrappe, Venloer Str. 30, D-50672 Köln
Impressum und Datenschutz
Schrappe, M.: P4P: Aktuelle Einschätzung, konzeptioneller
Rahmen und Handlungsempfehlungen, Version 1.2.1.

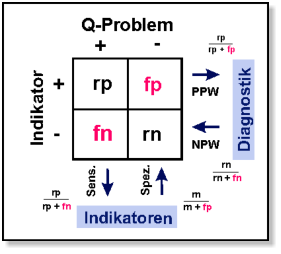
Tableau 7: Der Unterschied zwischen Indikatoren und diagnostischen Parametern in der ärztlichen (Differential)Diagnostik ist besonders
wichtig (s. Abb. 3). Eine gute diagnostische Methode muss in erster Linie eine therapeutische Entscheidung tragen können, daher darf sie keine
Erkrankung vorspiegeln, obwohl sie gar nicht vorliegt. Sie sollte also wenig falsch-positive Ergebnisse erbringen (hohe “Spezifität” wird dann
gesagt, es handelt sich aber im Grunde um einen hohen Positiven Prädiktiven Wert (PPW), da man allein von der Kenntnis des Testergebnisses
ausgeht). Anderenfalls würde eine falsche Therapie durchgeführt bzw. durch Unterlassen weiterer Untersuchungen die wirklich vorliegende
Erkrankung nicht erkannt. Aus diesem Grund wird von ärztlicher Seite immer wieder die mangelnde “Spezifität” von Indikatoren ins Feld geführt
(”war doch gar nicht so”) (z.B. Albrecht et al. 2013). Dabei wird aber der grundlegende Unterschied zu diagnostischen Test verkannt; anders in
der Diagnostik dürfen Indikatoren durchaus in einem gewissen Umfang falsch-positive Ergebnisse erbringen, wenn sie “dafür” aber alle
Qualitätsdefizite erkennen, die tatsächlich vorliegen (keine falsch-negativen Ergebnisse).
Beispiel: In einer Auswertung der lokalen §137-Qualitätssicherung kommt eine QM-Arbeitsgruppe zu dem Ergebnis, dass dem Ansprechen der
Indikatoren in den meisten Fällen gar kein Qualitätsdefizit zugrundeliegt (viele falsch-positive Ergebnisse, niedrige “Spezifität”) (Petzold et al.
2013). Interessant wäre es aber gewesen nachzuschauen, wie hoch der Anteil von (a priori) bekannten Qualitätsdefiziten ist, der von den
Indikatoren entdeckt wird (Sensitität). Bei niedriger Sensitivität wären die Indikatoren wirklich nutzlos, denn sie machen nicht valide auf
Probleme aufmerksam, die vorliegen. Wenn sie dagegen (mit vertretbarem Aufwand) alle Qualitätsprobleme identifizieren, ist die Validität hoch,
auch wenn es zusätzlich einige falsch-positive Ergebnisse geben sollte. Die Übertragung der EBM-Anforderungen für diagnostische Methoden
auf Indikatoren ist aus dieser Sicht diskussionswürdig (Schmitt et al. 2013).
Abb. 3: Gebrauch von Indikatoren in
Abgrenzung zu diagnostischen Tests. Bei
Indikatoren sind vor allem die falsch-
negativen Befunde wichtig (Sensitivität),
während bei der Diagnostik die Rate von
falsch-positiven Ergebnissen niedrig sein
muss (PPW, pos. prädiktiver Wert).



M. Schrappe
P4P: Aktuelle Einschätzung,
konzeptioneller Rahmen und
Handlungsempfehlungen